dTrader
The UK's first real-time AI-driven FX scalping platform — processing 50,000+ tick events per second, executing trades in under 5ms during peak volatility windows, powered by a self-training reinforcement learning agent and a transformer-based volatility prediction model that continuously improves on live market outcomes.
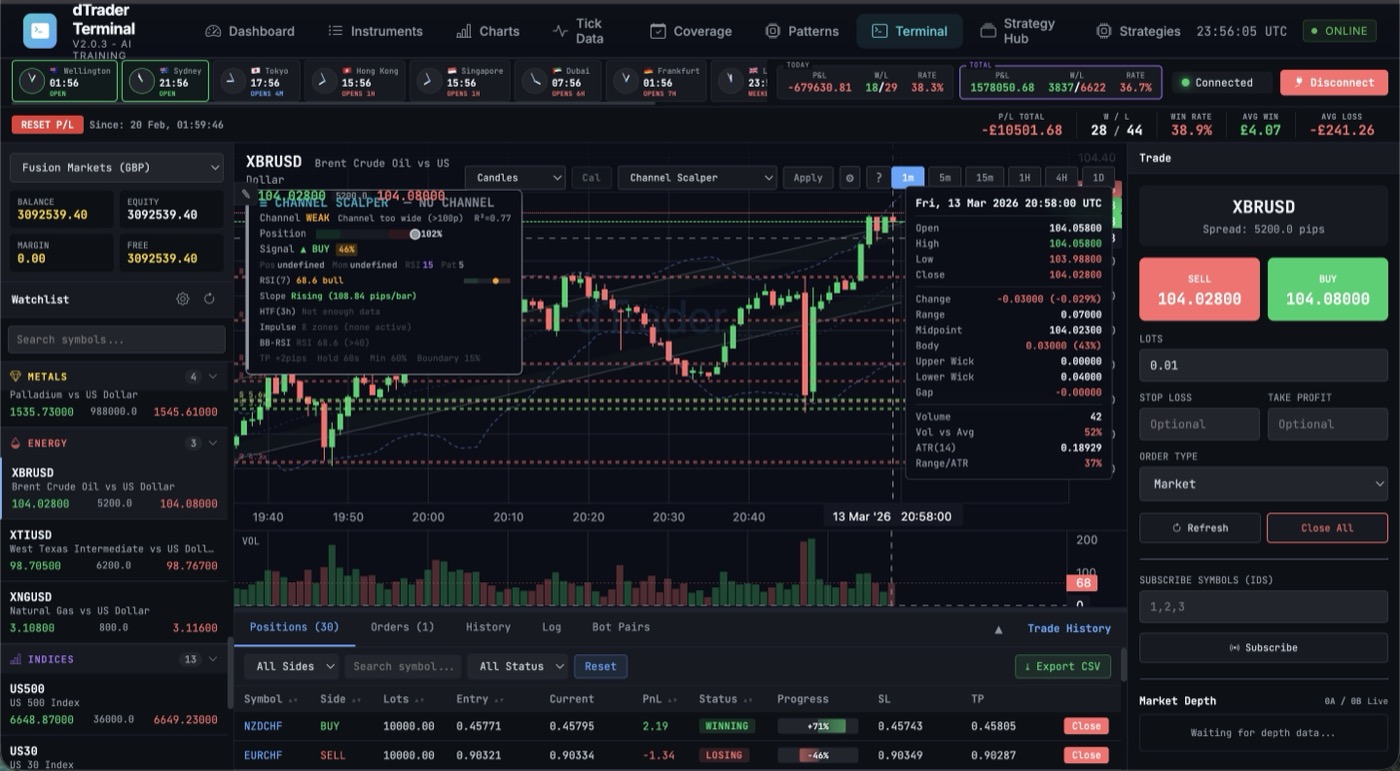
dTrader ingests FX tick data via FIX Protocol 4.4/5.0 connections to multiple Tier-1 liquidity providers simultaneously. Raw tick events are published to Apache Kafka topics (one topic per currency pair, partitioned by timestamp) at peak rates exceeding 50,000 tick events/second during London-New York session overlap.
Apache Flink processes the Kafka stream in real time with event-time watermarking and millisecond-precision windowing. Flink jobs compute: rolling VWAP across configurable windows (50ms to 5min), order book imbalance ratios, bid-ask spread evolution, and inter-pair correlation matrices — all updated on every tick, with exactly-once processing guarantees and sub-10ms end-to-end latency from tick ingestion to feature vector generation.
At the core of dTrader is a transformer-based time-series model (iTransformer architecture — inverted attention across variate dimensions rather than time steps) trained on 8 years of tick-level FX data across 28 major and cross pairs.
- Volatility Window Prediction: The model takes a 512-tick context window of multi-variate features (price, volume, spread, session, macro calendar proximity) and predicts the probability and magnitude of a high-volatility scalping window in the next 0–30 seconds. Flash Attention 3 reduces the attention computation to near-theoretical-peak FLOP/s on the H100 inference cluster, enabling sub-2ms forward pass latency.
- Entry / Exit Signal Generation: A secondary classification head produces directional confidence scores (long/short/flat) for each predicted volatility window. Only signals with confidence above a dynamically calibrated threshold trigger order generation.
- Reinforcement Learning Agent: A PPO-based (Proximal Policy Optimization) RL agent operates at the trade execution level. It observes real-time market microstructure state and decides position sizing, entry timing offset, and stop-loss placement within the scalping window. The reward function integrates realised P&L, slippage cost, and a Sharpe ratio penalty term to discourage excessive drawdown risk.
dTrader continuously improves its own models through an online learning loop. After each completed trade:
- Trade outcomes (entry, exit, slippage, realised P&L, market impact) are logged to a PostgreSQL time-series store.
- Successful and unsuccessful trade pairs are formatted as DPO (Direct Preference Optimization) preference datasets — chosen trades vs. rejected counterfactuals reconstructed by the market simulator.
- DPO fine-tuning runs nightly on the prediction model using the most recent 30 days of live trade outcomes, without requiring a separate reward model. The KL-divergence constraint against the reference model prevents catastrophic forgetting.
- The RL agent is updated via online PPO with a 60-second rollout horizon, adapting to intraday regime shifts within the same trading session.
This creates a compound learning flywheel: the more dTrader trades, the better its predictions, the better its entries, the higher its realised P&L per opportunity.
dTrader's order management system (OMS) is built in C++ with kernel-bypass networking (DPDK) for sub-microsecond order submission latency. A hardware-timestamped FPGA co-processor handles time-critical order routing decisions, bypassing OS scheduler jitter entirely.
Risk controls are enforced at the OMS level before any order exits the system:
• Real-time Value at Risk (VaR) computed via Monte Carlo simulation at 500,000 paths/second using GPU-accelerated sampling on H100 SXM5.
• Per-pair position limits, daily drawdown circuit breakers, and volatility-triggered exposure scaling.
• Regime change detection via a Hidden Markov Model (HMM) — automatically halts trading when market microstructure shifts to a regime outside the training distribution.
Forward pass inference runs on NVIDIA H100 SXM5 via vLLM with continuous batching across concurrent currency pair evaluations. Speculative decoding using a 180M-parameter draft model accelerates inference 2.6× wall-clock. Tensor parallelism (TP=4) distributes the iTransformer attention heads across 4 H100 GPUs, achieving 1.4ms mean forward pass latency at production load.
High-frequency inter-service communication runs over InfiniBand NDR 400Gb/s (sub-1µs MPI latency), critical for the tight timing loop between the Flink feature server, the AI inference engine, and the OMS.